717.1比特和2比特字符 有两种特殊字符。第一种字符可以用一比特0来表示。第二种字符可以用两比特(10 或 11)来表示。
现给一个由若干比特组成的字符串。问最后一个字符是否必定为一个一比特字符。给定的字符串总是由0结束。
示例 1:
1 2 3 4 5 输入: bits = [1, 0, 0] 输出: True 解释: 唯一的编码方式是一个两比特字符和一个一比特字符。所以最后一个字符是一比特字符。
示例 2:
1 2 3 4 5 输入: bits = [1, 1, 1, 0] 输出: False 解释: 唯一的编码方式是两比特字符和两比特字符。所以最后一个字符不是一比特字符。
注意:
1 <= len(bits) <= 1000.`
bits[i] 总是0 或 1.
代码
1 2 3 4 5 6 7 8 9 class Solution { bool Judge (vector <int >& bits) int i = bit .size () - 2 ; while ( i >= 0 && bits[i] == 1 ) i--; return (bits.size () - i)%2 == 0 ; } }
1386.两个数组间的距离值 给你两个整数数组 arr1 , arr2 和一个整数 d ,请你返回两个数组之间的 距离值 。
「距离值 」 定义为符合此描述的元素数目:对于元素 arr1[i] ,不存在任何元素 arr2[j] 满足 |arr1[i]-arr2[j]| <= d 。
示例 1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 输入:arr1 = [4,5,8], arr2 = [10,9,1,8], d = 2 输出:2 解释: 对于 arr1[0]=4 我们有: |4-10|=6 > d=2 |4-9|=5 > d=2 |4-1|=3 > d=2 |4-8|=4 > d=2 对于 arr1[1]=5 我们有: |5-10|=5 > d=2 |5-9|=4 > d=2 |5-1|=4 > d=2 |5-8|=3 > d=2 对于 arr1[2]=8 我们有: |8-10|=2 <= d=2 |8-9|=1 <= d=2 |8-1|=7 > d=2 |8-8|=0 <= d=2
示例 2:
1 2 输入:arr1 = [1,4,2,3], arr2 = [-4,-3,6,10,20,30], d = 3 输出:2
示例 3:
1 2 输入:arr1 = [2,1,100,3], arr2 = [-5,-2,10,-3,7], d = 6 输出:1
提示:
1 <= arr1.length, arr2.length <= 500-10^3 <= arr1[i], arr2[j] <= 10^30 <= d <= 100
算法1:线性扫描
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class solution { public : int findthevalue (vector <int >& arr1, vector <int >& arr2, int d) int cnt = arr1.size (); for (int i = 0 ; i < arr1.size (); ++i){ for (int j = 0 ; j < arr2.size (); ++j){ if (abs (arr1[i] - arr[j]) <= d){ cnt--; break ; }; } } return cnt; } }
算法2:二分查找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class solution {public : int findthevalue (vector <int >& arr1, vector <int >& arr2, int d) sort(arr2.begin (), arr2.end ()); int cnt = arr1.size (); for (int i = 0 ; i < arr1.size (); ++i){ unsigned p = lower_bound(arr2.begin (), arr2.end (), arr1[i]) - arr2.begin (); book ok = true ; if (p < arr2.size ()) ok &= (arr2[p] - arr1[i] > d); if (p - 1 >= 0 && p - 1 <= arr2.size ()) ok &= (arr[i] - arr[p - 1 ] > d); cnt += ok; } return cnt; } }
STL:lower_bound算法(复杂度$O(n)$)
(1)一共有三个参数:(开头,末尾,查找的值),可以用A.begin()和A.end()指定范围;
(2)返回值为不小于查找值 的元素所在位置的编号(注意,编号从0开始);否则越界截断;
(3)使用lower_bound算法需要注意两点:处理的数列已排序(sort算法),调用Algorithm库;
997. 找到小镇的法官 在一个小镇里,按从 1 到 N 标记了 N 个人。传言称,这些人中有一个是小镇上的秘密法官。
如果小镇的法官真的存在,那么:
小镇的法官不相信任何人。
每个人(除了小镇法官外)都信任小镇的法官。
只有一个人同时满足属性 1 和属性 2 。
给定数组 trust,该数组由信任对 trust[i] = [a, b] 组成,表示标记为 a 的人信任标记为 b 的人。如果小镇存在秘密法官并且可以确定他的身份,请返回该法官的标记。否则,返回 -1。
示例 1:
1 2 输入:N = 2, trust = [[1,2]] 输出:2
示例 2:
1 2 输入:N = 3, trust = [[1,3],[2,3]] 输出:3
示例 3:
1 2 输入:N = 3, trust = [[1,3],[2,3],[3,1]] 输出:-1
示例 4:
1 2 输入:N = 3, trust = [[1,2],[2,3]] 输出:-1
示例 5:
1 2 输入:N = 4, trust = [[1,3],[1,4],[2,3],[2,4],[4,3]] 输出:3
提示:
1 <= N <= 1000trust.length <= 10000trust[i] 是完全不同的trust[i][0] != trust[i][1]1 <= trust[i][0], trust[i][1] <= N
代码(信任度与被信任度)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class solution {public : int findthejudge (int N, vector <vector <int >>& trust) vector <vector <int >> V (N+1 , vector (2 ,0 )) for (int i = 0 ; i < trust.size (); ++i){ V[trust[i][0 ]][0 ]++; V[trust[i][1 ]][1 ]++; } for (int i = 1 ; i <= N; ++i){ if (V[i][0 ] == 0 && V[i][1 ] == N-1 ){ return i; } } return -1 ; } }
总结:vector的相关用法
78. 子集 给定一组不含重复元素 的整数数组 nums ,返回该数组所有可能的子集(幂集)。
说明: 解集不能包含重复的子集。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 输入: nums = [1,2,3] 输出: [ [3], [1], [2], [1,2,3], [1,3], [2,3], [1,2], [] ]
题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public : vector <vector <int >> subsets (vector <int >& nums) vector <vector <int >> ans; int size = nums.size (); int N = 1 << size ; for (int i = 0 ; i < N; ++i){ vector <int > v; for (int j = 0 ; j < size ; ++j){ if (i & (1 << j)){ v.push_back(nums[j]); } } ans.push_back(v); } return ans; } }
739. 每日温度 根据每日 气温 列表,请重新生成一个列表,对应位置的输出是需要再等待多久温度才会升高超过该日的天数。如果之后都不会升高,请在该位置用 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示: 气温 列表长度的范围是 [1, 30000]。每个气温的值的均为华氏度,都是在 [30, 100] 范围内的整数。
思路
这道题最容易想到的方法就是做一个二重循环,依次找到每个温度后的最大上升天数,但很显然,时间复杂度为$O(n^2)$,很容易就超时了。
此时可以考虑使用单调栈。单调栈是一种专门对数组进行排序的数据结构,时间复杂度为$O(n)$。
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class solution :public : vector <int > dailyTemperatures (vector <int > T) int size = T.size (); vector <int > ans (size ,0 ) stack <int > res; for (int i = 0 ; i < size ; ++i){ if (res.empty()) res.push(i); while (!res.empty() && T[j] > T[res.top()]){ ans[res.top()] = i - res.top(); res.pop(); } res.push(i); } return ans; }
287. 寻找重复数 给定一个包含 n + 1 个整数的数组 nums ,其数字都在 1 到 n 之间(包括 1 和 n ),可知至少存在一个重复的整数。假设只有一个重复的整数,找出这个重复的数。
示例 1:
示例 2:
说明:
不能 更改原数组(假设数组是只读的)。只能使用额外的$ O(1) $的空间。
时间复杂度小于 $O(n^2)$ 。
数组中只有一个重复的数字,但它可能不止重复出现一次。
解决方案
最容易考虑的思路是先排序,之后再遍历一遍看是否存在重复元素。但在不允许更改原数组的情形下,无法满足上述空间限制,则需要考虑新的方法。事实上,本题目存在一种特殊方法:循环检测方法
考虑索引,用nums[i]表示i下一步的方向(能够保证上述操作进行的条件就是整数分布在1到n之间);由此会发现若存在重复数,那么最后无法到达n,会导致循环的出现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class solution {public : int findDuplicate (int [] nums) int slow = nums[0 ]; int quick = nums[0 ]; do { slow = nums[slow]; quick = nums[nums[quick]]; }while (slow != quick); int ptr_1 = nums[0 ]; int ptr_2 = slow; while (ptr_1 != ptr_2){ ptr_1 = nums[ptr_1]; ptr_2 = nums[ptr_2]; } return ptr_1; } }
二分查找
由于题目给定了数组中数字范围,即1到n,则最终的答案也在二者之中;可以考虑使用二分法,依次考虑小于mid的数字的出现的次数,若比较大, 则再做一次二分查找,最后即可以找到目标值;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class solution { public int findDuplicate (int [] nums) int size = nums.length; int l = 1 , r = size - 1 ; while (l < r){ int mid = (l + r)/2 ; for (int num:nums){ if (num <= mid) cnt++; } if (cnt > mid){ r = mid; }else { l = mid + 1 ; } } return l; } }
73. 矩阵置零 给定一个 m x n 的矩阵,如果一个元素为 0,则将其所在行和列的所有元素都设为 0。请使用原地 。
示例 1:
1 2 3 4 5 6 7 8 9 10 11 12 输入: [ [1,1,1], [1,0,1], [1,1,1] ] 输出: [ [1,0,1], [0,0,0], [1,0,1] ]
示例 2:
1 2 3 4 5 6 7 8 9 10 11 12 输入: [ [0,1,2,0], [3,4,5,2], [1,3,1,5] ] 输出: [ [0,0,0,0], [0,4,5,0], [0,3,1,0] ]
进阶:
一个直接的解决方案是使用 O(m**n ) 的额外空间,但这并不是一个好的解决方案。
一个简单的改进方案是使用 O(m + n ) 的额外空间,但这仍然不是最好的解决方案。
你能想出一个常数空间的解决方案吗?
我的思路
设置两个空数组用于存储行列指标,之后再做处理;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class solution { public : void setZeroes (vector <vector <int >> matrix) int m = matrix.size (), n = matrix[0 ].size (); if (m == 0 ||n == 0 ) return ; vector <int > label_i, label_j; for (int i = 0 ; i < m; ++i){ for (int j = 0 ; j < n; ++j){ if (matrix[i][j] == 0 ){ label_i.push_back(i); label_j.push_back(j); } } } int len = label_i.size (); for (int k = 0 ; k < len; ++K){ int tmpi = label_i[k], tmpj = label_j[k]; for (int i = 0 ; i < m; ++i) matrix[i][tmpj] = 0 ; for (int j = 0 ; j < n; ++j) matrix[tmpi][j] = 0 ; } } }
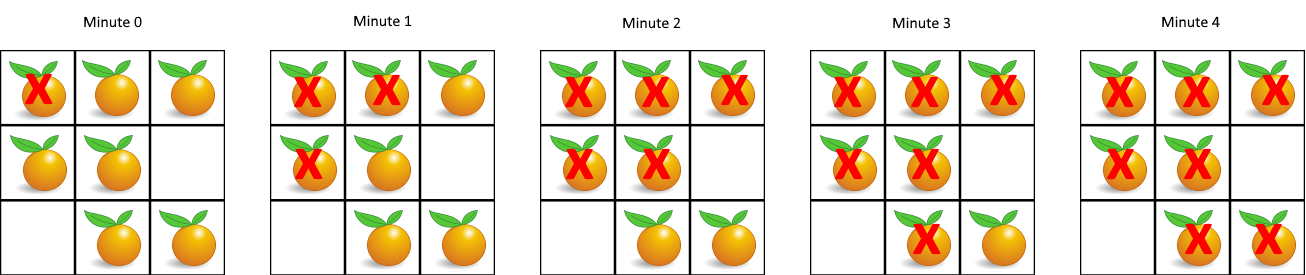
994. 腐烂的橘子 在给定的网格中,每个单元格可以有以下三个值之一:
值 0 代表空单元格;
值 1 代表新鲜橘子;
值 2 代表腐烂的橘子。
每分钟,任何与腐烂的橘子(在 4 个正方向上)相邻的新鲜橘子都会腐烂。
返回直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1。
示例 1:
1 2 输入:[[2,1,1],[1,1,0],[0,1,1]] 输出:4
示例 2:
1 2 3 输入:[[2,1,1],[0,1,1],[1,0,1]] 输出:-1 解释:左下角的橘子(第 2 行, 第 0 列)永远不会腐烂,因为腐烂只会发生在 4 个正向上。
示例 3:
1 2 3 输入:[[0,2]] 输出:0 解释:因为 0 分钟时已经没有新鲜橘子了,所以答案就是 0 。
提示:
1 <= grid.length <= 101 <= grid[0].length <= 10grid[i][j] 仅为 0、1 或 2
1227. 飞机座位分配概率(动态规划) 有 n 位乘客即将登机,飞机正好有 n 个座位。第一位乘客的票丢了,他随便选了一个座位坐下。
剩下的乘客将会:
如果他们自己的座位还空着,就坐到自己的座位上,
当他们自己的座位被占用时,随机选择其他座位
第 n 位乘客坐在自己的座位上的概率是多少?
示例 1:
1 2 3 输入:n = 1 输出:1.00000 解释:第一个人只会坐在自己的位置上。
示例 2:
1 2 3 输入: n = 2 输出: 0.50000 解释:在第一个人选好座位坐下后,第二个人坐在自己的座位上的概率是 0.5。
提示:
参考解答
1 2 3 (1)第一位乘客若选择了本就是其自己的位置,则后面的人都会按顺序入座,第n位乘客入座概率为1/n; (2)第一位乘客刚好选择了第n位乘客的位置,则第n位乘客成功入学概率为0; (3)第一位乘客选择了第i位乘客(i不为0或1)的座位,则可把第i位乘客看作忘带票乘客选择n-1个座位,写出递推公式;
236.二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
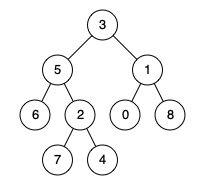
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
示例 1:
1 2 3 输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出: 3 解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
示例2
1 2 3 输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出: 5 解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。
说明:
所有节点的值都是唯一的。
思路
p和q的分布存在两种情况,在同一侧或者不同侧中,则考虑对左右子树分别进行递归操作;
递归的返回条件为root为空或者root为p或者q中一个;
之后判断:若左右子树均有返回值,则说明存在于左右子树中,返回当前节点;反之,则非空返回结点为公共节点;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct TreeNode { int val; TreeNode* left; TreeNode* right; }; class solution { public : TreeNode lowestCommonAncestor (TreeNode *root, int p, int q) { if (!root || root == p || root == q) return root; TreeNode *left = lowestCommonAncestor(root->left, p, q); TreeNode *right = lowestCommonAncestor(root->right, p, q); if (left && right) return root; else return left?left: right; } }
1319. 连通网络的操作次数 用以太网线缆将 n 台计算机连接成一个网络,计算机的编号从 0 到 n-1。线缆用 connections 表示,其中 connections[i] = [a, b] 连接了计算机 a 和 b。
网络中的任何一台计算机都可以通过网络直接或者间接访问同一个网络中其他任意一台计算机。
给你这个计算机网络的初始布线 connections,你可以拔开任意两台直连计算机之间的线缆,并用它连接一对未直连的计算机。请你计算并返回使所有计算机都连通所需的最少操作次数。如果不可能,则返回 -1 。
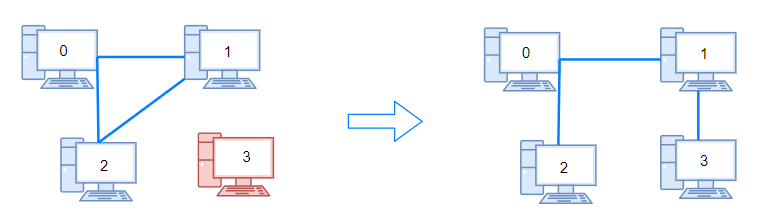
示例 1:
1 2 3 输入:n = 4, connections = [[0,1],[0,2],[1,2]] 输出:1 解释:拔下计算机 1 和 2 之间的线缆,并将它插到计算机 1 和 3 上。
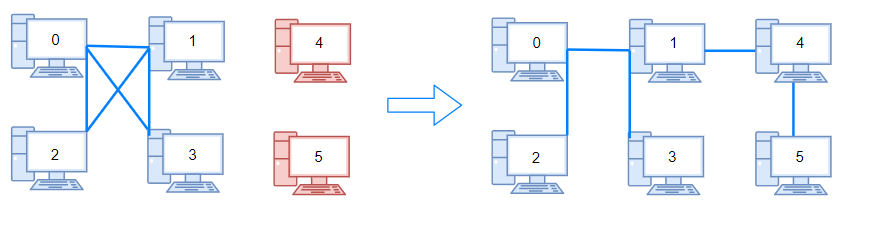
示例 2:
1 2 输入:n = 6, connections = [[0,1],[0,2],[0,3],[1,2],[1,3]] 输出:2
示例 3:
1 2 3 输入:n = 6, connections = [[0,1],[0,2],[0,3],[1,2]] 输出:-1 解释:线缆数量不足。
示例 4:
1 2 输入:n = 5, connections = [[0,1],[0,2],[3,4],[2,3]] 输出:0
提示:
1 <= n <= 10^51 <= connections.length <= min(n*(n-1)/2, 10^5)connections[i].length == 20 <= connections[i][0], connections[i][1] < nconnections[i][0] != connections[i][1]没有重复的连接。
两台计算机不会通过多条线缆连接。
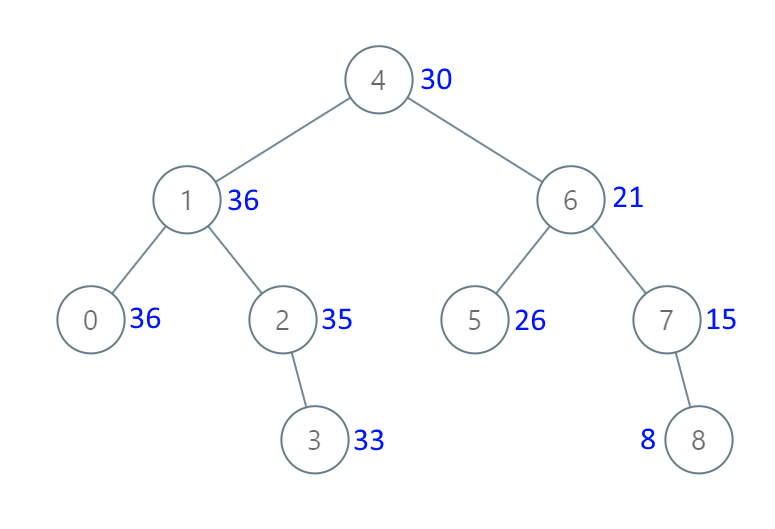
1038. 从二叉搜索树到更大和树 难度中等46收藏分享切换为英文关注反馈
给出二叉 搜索 树的根节点,该二叉树的节点值各不相同,修改二叉树,使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
节点的左子树仅包含键 小于 节点键的节点。
节点的右子树仅包含键 大于 节点键的节点。
左右子树也必须是二叉搜索树。
示例:
1 2 输入:[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8] 输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
提示:
树中的节点数介于 1 和 100 之间。
每个节点的值介于 0 和 100 之间。
给定的树为二叉搜索树。
解题思路
1 2 二叉搜索树最重要的性质便是右侧的数值大于左侧,本题中替换的数值大小便是右侧的所有键值之和。 采取左序遍历的方式,求出所有元素之和,再依次减去自身元素即可;
参考代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 struct TreeNode { int val; TreeNode* left; TreeNode* right; TreeNode(int x): val(x), left(NULL ), right(NULL ){} }; class solution :public : int sum = 0 ; queue <int > qu; void sum_num (TreeNode *root) if (root){ sum_num(root->left); sum += root->val; qu.push(root->val); sum_num(root->right); } } void insertval (TreeNode *root) if (root){ insertval(root->left); root->val = sum; sum -= qu.front(); qu.pop(); insertval(root->right); } } TreeNode* bstToGst (TreeNode* root) { sum_num(root); insertval(root); return root; }
50.利用快速幂算法实现pow(x,n)函数 基本思路,采用递归的想法,将$x^n$看作$(x^{n/2})^2$即可(快速幂算法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 double FastPow (double x, int n) if (n == 0 ) return 1.0 ; double half = FastPow(x, n/2 ); if (n%2 == 0 ){ return half*half; }else { return half*half*x; } } double pow (double x, int n) if (n == 0 ) return 1.0 ; if (n < 0 ){ x = 1 /x; n = -n; } return FastPow(x,n); }
102. 二叉树的层序遍历 给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
示例: [3,9,20,null,null,15,7],
返回其层次遍历结果:
1 2 3 4 5 [ [3], [9,20], [15,7] ]
思路
对于层序遍历,最开始想到的便是借助队列使用宽度有限搜索的方法
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class solution :public : vector <vector <int >> ans (TreeNode* root) if (root == NULL ) return {}; vector <vector <int >> ans; queue <TreeNode*> qu; qu.push_back(root); while (!qu.empty()){ vector <int > tmp; int n = qu.size (); while (n>0 ){ TreeNode* t = qu.front(); qu.pop(); tmp.push_back(t->val); if (t->left != NULL ) qu.push(t->left); if (t->right != NULL ) qu.push(t->right); n--; } ans.push_back(tmp); } return ans; }
28. 实现 strStr() 给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1 。
示例 1:
1 2 输入: haystack = "hello", needle = "ll" 输出: 2
示例 2:
1 2 输入: haystack = "aaaaa", needle = "bba" 输出: -1
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() ) 定义相符。
解题思路
方法一、使用#include中的find函数,如果找到needle,则返回起点;若无法找到needle,则返回haystack.npos,只需判断返回值即可。(但这种方法比较偷懒,没啥价值)
1 2 3 4 5 int strStr (string text , string pattern) if (text .find (pattern) == text .npos) return -1 ; else return text .find (pattern); }
方法二、Brute-Force算法:暴力求解,从头到尾遍历一遍,遇见不相等则跳过;
方法三、优化Brute-Force:“减少爬行趟数”——跳过不可能的那部分字符串
(1)pattern构造next数组:next[i] 表示 0 ~ i 这一个子串,使得前k个字符 恰好等于后k个字符 的最大的k;
如果失配在 P[r], 那么P[0]~P[r-1]这一段里面,前next[r-1]个字符恰好和后next[r-1]个字符相等 ——也就是说,我们可以拿长度为 next[r-1] 的那一段前缀,来顶替当前后缀的位置,让匹配继续下去!
KMP算法的精髓:快速求next数组
1 2 3 4 5 6 7 8 9 10 11 vector <int > next (pattern.size () + 1 ) int j = -1 , i = 0 ;next[i] = j; while (i < pattern.size ()){ while (j >= 0 && pattern[i] != pattern[j]) j = next[j]; i++, j++; b[i] = j; }
通过建立next数组,可以快速得到每次需要跳过的步骤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class solution {public : int strStr (string text , string pattern) if (pattern.size () == 0 ) return 0 ; if (text .size () == 0 ) return -1 ; int j = -1 , i = 0 ; vector <int > next (pattern.size () + 1 ) next[i] = j; while (i < pattern.size ()){ while (j >= 0 && pattern[i] != pattern[j]) j = b[j]; i++, j++; next[i] = j; } j = 0 , i = 0 ; while (j < text .size ()){ while (i >= 0 && pattern[i] != text [j]) i = b[i]; i++, j++; if (i == pattern.size ()) return j - pattern.size (); } return -1 ; } }
This is copyright.